RubyKaigi 2024 に参加しました。
この記事でも参照していますが、"Breaking the Ruby Performance Barrier" という講演が非常にエキサイティングでした。
僕も YJIT の力を感じたくなり、zlib gem を pure Ruby で書き直してみて、C拡張に比べてどのぐらいパフォーマンスが出るか検証する、というのをちょっとづつ進めています。
zlib とは
zlib は、Deflate (ZIP とか gzip とかで使われる圧縮アルゴリズム) を実装するライブラリです。
Ruby から zlib を利用する gem として zlib が存在します。
この gem は端から端まで C 拡張で記述されており、 ext/zlib/zlib.c にすべてのコードが記述されています(テストは Ruby で書かれている)。
リライト方針
ゼロから一気に全部書き換えることを目指すと心が折れそうなので、以下のような手順で漸進的にリライトを進めています。
こんな感じになります(この diff では3つのメソッドを置き換えている):

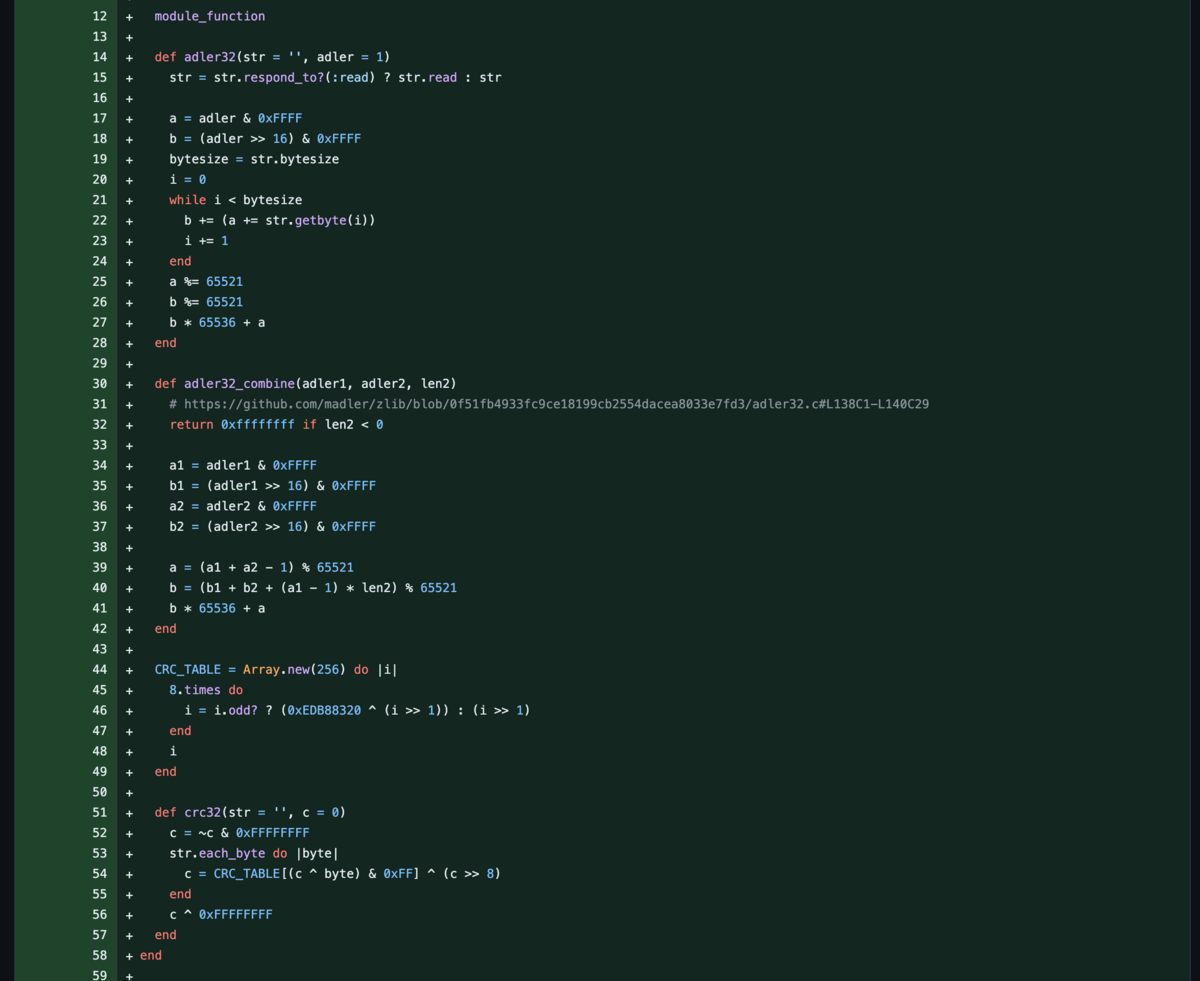
このようにすることで、テストが通ることを都度チェックできるので確実に進められますし、ちょっとづつ進捗を感じることができるので良いです。
クラスをリライトするときはこの手法が使えず、クラスに所属するメソッドをすべて同時に書き換える必要がある気がしてますが、まあどうにかなるでしょう。
進捗
本日時点では、以下の3つのメソッドの置き換えが完了しています。
Zlib.adler32Zlib.adler32_combineZlib.crc32
そのうち Zlib.adler32 については、ベンチマークやプロファイルを取りつつ最適化を行いました(後述)が、結構大変な思いをしました。
そのため、下の2つについてはとりあえず動けば良しということで真面目に最適化してないです。
一通り書き直したらベンチマークを取ろうと思います。
レポジトリはこちらになります:
Comparing ruby:master...genya0407:feature/pure-ruby · ruby/zlib · GitHub
Zlib.adler32 の最適化
前述のように、Zlib.adler32 を実装するときは真面目に最適化を行ったので、そのベンチマーク結果を書いておきます。
なお、adler32 自体の説明については Wikipedia を参照してもらうのが良いと思いますが、要はバイナリ列のチェックサムを計算するメソッドです。
ベンチマークは以下のようなコードで行いました。
require 'benchmark' require 'securerandom' require_relative 'lib/zlib' RubyVM::YJIT.enable long_string = SecureRandom.bytes(10_000) Benchmark.bmbm do |x| x.report('C-ext') do i = 0 while i < 1000 Zlib.adler32(long_string) i += 1 end end x.report('pure Ruby') do i = 0 while i < 1000 Zlib.adler32_pure(long_string) i += 1 end end end
ローカル環境(Apple M1 Pro)でこのスクリプトを動かしてみたところ、結果は以下のようになりました。
Rehearsal ---------------------------------------------
C-ext 0.000811 0.000018 0.000829 ( 0.000825)
pure Ruby 0.061622 0.000084 0.061706 ( 0.061824)
------------------------------------ total: 0.062535sec
user system total real
C-ext 0.000618 0.000001 0.000619 ( 0.000616)
pure Ruby 0.046205 0.000026 0.046231 ( 0.046362)
pure Ruby 実装の方がだいたい 75 倍ぐらい遅いですね。
ちなみに上記は Ruby 3.3.1 を使ったときの結果ですが、Ruby 3.4.0-preview1 を使うと以下のような結果になりました。
Rehearsal ---------------------------------------------
C-ext 0.000767 0.000017 0.000784 ( 0.000780)
pure Ruby 0.035132 0.000063 0.035195 ( 0.035337)
------------------------------------ total: 0.035979sec
user system total real
C-ext 0.000645 0.000001 0.000646 ( 0.000645)
pure Ruby 0.020487 0.000003 0.020490 ( 0.020547)
pure Ruby 実装の方がだいたい 30 倍ぐらい遅いので、3.3.1 → 3.4.0-preview1 で 2 倍ぐらいは速くなってることがわかります。
なお 3.4.0-preview1 でも YJIT を切ると以下のような結果になります。
Rehearsal ---------------------------------------------
C-ext 0.000837 0.000018 0.000855 ( 0.000851)
pure Ruby 0.432514 0.000175 0.432689 ( 0.433537)
------------------------------------ total: 0.433544sec
user system total real
C-ext 0.000662 0.000002 0.000664 ( 0.000662)
pure Ruby 0.426348 0.000069 0.426417 ( 0.426842)
pure Ruby 実装のほうが 645 倍ぐらい遅いので、YJIT によって 20 倍ぐらい速くなることがわかります。
YJIT はすごいし、進歩も目覚ましいですね。。。
pure Ruby 実装の最適化をしたときの感想
Zlib.adler32 の pure Ruby 実装は C 拡張に比べて 30倍 ぐらい遅いと書きましたが、実はこれは結構頑張って最適化をやった結果です。適当に書くともっと遅いです。
たとえば String から byte 列を取り出すのに、当初は String#bytes や String#each_byte が使っていましたが、これらはものすごく遅いです(ruby-prof を使ってプロファイルを取った)。
String#unpack も使ってみましたが、これも結構遅かったです。
Shopify/protoboeuf の実装を軽く見てみたところ String#getbyte が使われていたので試してみたら、これが一番速かったです。
次にボトルネックになったのは Integer#+ に時間がかかるというやつです。
初めは、modulo 演算をするタイミングの問題で Bignum になってしまい、多倍長整数の足し算によって遅くなってるのかな?と疑っていましたが、Fixnum は 63bit もあり、unsigned char を足し算しただけではそんなに簡単に Bignum には突入しないので、単純に Fixnum (実態は long) の足し算に時間がかかっているようです。
このボトルネックは今でも解決できてないのですが、おそらく以下の問題があるのではないかと考えています。
- while ループ のカウンタをインクリメントする回数が多い?
- libz の実装では 16 バイトまとめて計算することでカウンタをインクリメントする回数を減らしているようだが、Ruby ではこの最適化ができない
- zlib/adler32.c at 0f51fb4933fc9ce18199cb2554dacea8033e7fd3 · madler/zlib · GitHub
- Integer は immutable なので inplace な操作に比べて遅い?
- たかが long とはいえ、都度新しいオブジェクトを生成しているのは遅い気がする
- そもそも short で足りるところを long 使ってるのでそれも遅そう
- GitHub - osyoyu/pf2: A sampling-based profiler for Ruby を使えば C の中のプロファイルが取れるんじゃないかと思って使ってみたが、何も情報が取れなかった。速すぎて sampling profiler ではうまくプロファイルできないのかもしれない。
いずれにせよ、Ruby は C に比べて最適化に使える(危険な)手段が少ないナアとは感じました。 Ruby でそんなことすんなという話はあると思います。
まとめ
いわゆる一つの Kaigi Effect として、zlib を pure Ruby で書き直すという試みを進めています。
Zlib.adler32 については最適化を頑張って、C拡張の30倍遅い程度まで高速化できました。
引き続き暇を見つけて書き換えを進めていこうと思います。
コメント・感想などあれば @genya0407@social.genya0407.link までいただけると嬉しいです(ブクマも歓迎)。